
m6平台登录入口AI从GPU席卷至MCU内存的重要性与算力等同
2024-12-22 12:24:03 | 来源:米乐m6网页版登录入口 作者:M6米乐手机登录APP入口
的不懈追求中,似乎绝大多数人都把重心放在了算力上。然而决定真正AI计算表现的,还有内存这一重要组成部分。为此,除了传统的标准内存选项外,市面上也出现了专门针对AI进行优化的内存。
无论是的服务器GPU,还是一众初创公司推出的AI加速器,我们都可以看到HBM出现的越来越频繁,比如英伟达H100、谷歌TPU等等。美光、SK海力士和三星厂商都在布局这类超高带宽内存,用于解决 AI计算中时常出现的内存墙问题。
以LLM模型的训练负载为例,HBM3内存与处理器可以与处理器以最高6.4Gb/s的接口速率相连,并实现3.2TB/s的超大带宽。而且在3D堆叠技术的支撑下,SoC芯片的面积依然控制在一个合理的范围内。超大的带宽显著减少了模型训练时间,所以我们才能看到如此快的LLM模型更迭速度。
当把模型推向终端应用时,效率就和效能一样重要了。推理带来的计算成本异常庞大,所以我们需要更低的系统功耗。而HBM内存恰好可以在维持“较低”速率的同时,实现与处理器的“近距离接触”和大带宽,从而进一步降低整体系统功耗。
当然了,HBM也并非那么完美,不然我们也不会只在服务器级别的产品上看到它们。随着HBM而来的是设计复杂度和更高的成本,比如需要额外设计硅中介层等等。但还是由于吃到了AI红利,HBM的成本也在慢慢降低,甚至有的初创公司在首个AI芯片上就直接采用HBM3内存,为的就是充分释放AI芯片的计算性能。
随着AI热潮的袭来,我们也看到了边缘端不少AIoT产品开始追逐这一风口,尤其是智能音箱等具备交互能力的设备。然而以这类设备主用的MCU芯片而言,本身计算性能就难以与GPU这样的高性能AI加速器媲美,更别说内存带宽了。
为此,英飞凌推出了HyperRAM这一高速内存,相较传统的pSRAM,HyperRAM成了更高效简洁的解决方案。HyperRAM基于HyperBus这一接口开发,相较于其他DRAM内存方案,HyperRAM并不见得有压倒性的带宽优势,比如最新的HyperRAM 3.0版本,其带宽最高可达800MB/s。
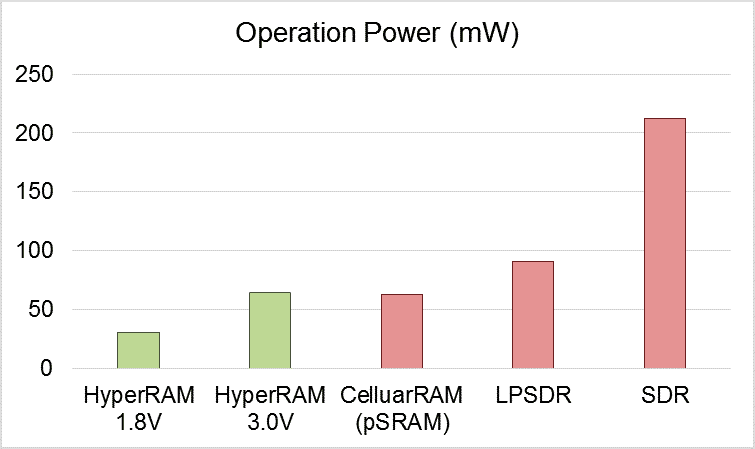
但在同等带宽下工作时,HyperRAM可以提供更少的引脚数和更低的功耗,对于不少可穿戴应用来说,采用HyperRAM不仅降低所需的PCB面积,也进一步降低了功耗,提高了这类设备的续航能力。根据华邦电子提供的数据,同样64MB的内存,HyperRAM可以实现比SDRAM低数十倍的待机功耗。
时至今日,我们已经看到不少顶尖MCU厂商,诸如NXP瑞萨TI等,都已经提供了支持HyperBus接口的MCU。新思、Cadence等厂商也开始提供HyperBus控制IP,华邦电子也加入HyperRAM的供应生态链中来,HyperRAM已然成了AIoT应用中MCU乃至MPU外部RAM的理想选择。
无论是HBM还是HyperRAM,都是AI时代下开始发光发热的内存选择。他们的出现不仅为市场提供了更灵活的设计选择,也进一步推动了内存技术在设计、工艺和封装上的进步。未来随着内存技术迈入下一个阶段,或许不只有AI应用能从中受益。
来自一位用户的咨询,麻烦帮忙解答,越详细越好,有图有,可以适当提供一些英飞凌解决方案和产品推荐。 用
算力,谁就拥有足够的话语权,这话有点难听,但事实确是如此。尤其是伴随着AIGC的出现,“向大众市场下沉”是
应用带来强劲算力支持 /
知识科普 /
的要求呈现爆发式增长,速度远超摩尔定律 通用计算时代终结,数据中心走向加速器时代。未来10年,FPGA的
组成部分,电源就像“的心脏”,为系统的硬件输送血液(电),要是心脏(电源)运行不正常或供血(电)不足,会导致系统不运行或运行不稳定,在设计之前应该对核心
野望 /
电路板表面向镀通孔中填铜所需的延展性。 方案介绍 基于新唐ML51开发的电池管理系统(BMS)—超低功耗
以上分享了很多关于器件布局不当,而引发的生产问题,下面分享一个可以一键解决这些问题的工具:华秋DFM软件,可以提前检测元器件布局的安全间距,避免存在可组装性问题。 华秋DFM的组装分析功能
m6平台登录入口 上一篇:2023年空调选购指南空调哪个牌子好? 下一篇:天然气气体涡轮流量计故障分析与注意事项